Text classification with the Longformer
24 Nov 2020In a previous post I explored how to use Hugging Face Transformers Trainer class to easily create a text classification pipeline. The code was pretty straightforward to implement, and I was able to obtain results that put the basic model at a very competitive level with a few lines of code. In that post I also discussed one of the main drawbacks of the first generation of Transformers and BERT based architectures; the sequence length is limited to a maximum of 512 characters. The reason behind that limitation is the fact that self-attention mechanism scales quadratically with the input sequence length O(n^2). Given the need to process longer sequences of text a second generation of attention based models, that drastically reduce the memory footprint of attention mechanisms, have been proposed; see this really useful review of 2nd gen transformer models that try to overcome this limitation. New models such as the Reformer by Google proposes a series of innovations to the traditional transformer architecture locality sensitive hashing (LSH), lsh attention, chunked feed forward layers, etc. This post from Hugging Face has a really in-depth explanation of all the details behind Reformer. This model can process sequences of half a million tokens with as little as 8GB of RAM. However, one big drawback of the model for downstream applications is the fact that the authors have not released pre trained weights of their model and at the time of publication of this post there is no freely available model pretrained on a large corpus.
Another very promising model, and the subject of this post, is the Longformer by researchers from Allen AI Institute. The Longformer can process sequences of thousands of characters without facing the memory bottleneck of BERT like architectures, and achieved SOTA at the time of publication in several benchmarks. The Longformers uses a new variation of attention, called local attention where every token only attends to tokens in the vicinity defined by a window w where each token attends to $\frac{1}{2}\ w$ tokens to the left and to the right. To increase the receptive field the authors also applied dilation to the local window so they can increase the size of w without incurring in additional memory costs. A dilation is simply a “hole”, meaning the token simply skips that token thus allowing attention to reach farther tokens. The performance is not hurt since the transformer architecture has multiple attention heads across multiple layers and the different layers and head learn and attend different properties of texts and tokens. In addition to the local attention the authors also included a token that is attended globally so it can be used in downstream tasks, just like thee CLS token of BERT. One of the interesting aspects of this model is the fact that the authors created their own CUDA kernel to calculate the attention scores of the sliding window attention. This operation is called matrix banded multiplication but is not implemented in Pytorch/Tensorflow. Thanks to our friends from Hugging Face an implementation with standard CUDA kernels is available altough it does not have all the capabilities the authors of the Longformer model describe in their paper it is suitable for finetuning downtream tasks.
The authors tested the model with an autoregressive model to process sequences of thousands of tokens, achieving state of the art on text8 and enwik8. They also tested the model on downstream tasks by finetuning the model with the weights of RoBERTA to conduct masked token prediction (MLM) of one third of the real news dataset, and a third of the stories dataset. The authors pretrained two variations of the model a base model (with 12 layers) and a large model (30 layers). Both models were trained for 65K gradient updates with sequences of length 4,096 and batch size 64. Once the pretraining was completed they tested the models on downstream tasks such as question answering, coreference resolution and document classification. The model achieved SOTA results on the WikiHop TriviaQA datasets and in the hyper partisan data. For the IMDB dataset the authors achieved 95.7 percent accuracy, a small increase from the 95.3 percent accuracy reported by RoBERTa.
Given all these nice features I decided to try the model and see how it compares to RoBERTA on the IMDB data, the iris dataset of text classification. For this script I re used a lot of the code from the previous post and used the pretrained model offered by Allen AI available in the model hub of Hugging Face.
import pandas as pd
import datasets
from transformers import LongformerTokenizerFast, LongformerForSequenceClassification, Trainer, TrainingArguments, LongformerConfig
import torch.nn as nn
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from tqdm import tqdm
import wandb
import os
One of the cool features about this model is that you can specify the attention sliding window across different levels; the authors exploited this design for the autoregressive language model using different sliding windows for different layers. If this parameter is not changed it will assume a default of 512 across all the different layers.
config = LongformerConfig()
config
LongformerConfig {
"attention_probs_dropout_prob": 0.1,
"attention_window": 512,
"bos_token_id": 0,
"eos_token_id": 2,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "longformer",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"sep_token_id": 2,
"type_vocab_size": 2,
"vocab_size": 30522
}
train_data, test_data = datasets.load_dataset('imdb', split =['train', 'test'],
cache_dir='/media/data_files/github/website_tutorials/data')
For my implementation of the model, and to save speed in the pretraining I chose the maximum length of 1024 characters which covers close to 98 percent of all the documents in the dataset. Before using my brand new and still pretty much impossible to find RTX3090, I use to set the gradient checkpointing parameter to true. This saves a huge amount of memory and allows models such as the longformer to train on more modest GPU’s such as my old EVGA GeForce GTX 1080. Gradient checkpointing is a really nice way to re use weights in the neural network and allows massive models to run on more modest settings with a 30 percent increase in training time. The original paper discussing gradient checkpointing can be found here and a nice discussion of gradient checkpointing can be hound here.
Additionally, to save memory and increase training time I also used mixed precision training to speed up the computation time of the training process. If you want to learn more about mixed precision I recommend this blogpost. With the combination of mixed precision, gradient accumulation, and gradient checkpoint you can set the length to 4096.
# load model and tokenizer and define length of the text sequence
model = LongformerForSequenceClassification.from_pretrained('allenai/longformer-base-4096',
gradient_checkpointing=False,
attention_window = 512)
tokenizer = LongformerTokenizerFast.from_pretrained('allenai/longformer-base-4096', max_length = 1024)
The model gives a warning anout needing to train the model first before usage in downstream tasks.
model.config
LongformerConfig {
"_name_or_path": "allenai/longformer-base-4096",
"attention_mode": "longformer",
"attention_probs_dropout_prob": 0.1,
"attention_window": [
512,
512,
512,
512,
512,
512,
512,
512,
512,
512,
512,
512
],
"bos_token_id": 0,
"eos_token_id": 2,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"ignore_attention_mask": false,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 4098,
"model_type": "longformer",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"sep_token_id": 2,
"type_vocab_size": 1,
"vocab_size": 50265
}
# define a function that will tokenize the model, and will return the relevant inputs for the model
def tokenization(batched_text):
return tokenizer(batched_text['text'], padding = 'max_length', truncation=True, max_length = 1024)
train_data = train_data.map(tokenization, batched = True, batch_size = len(train_data))
test_data = test_data.map(tokenization, batched = True, batch_size = len(test_data))
We make sure our truncation strategy and the padding are set to the maximun length
len(train_data['input_ids'][0])
1024
Once the tokenization process is finished we can use the set the column names and types. One thing that is important to note is that the LongformerForSequenceClassification implementation by default sets the global attention to the CLS token, so there is no need to further modify the inputs.
In the paper the authors trained for 15 epochs, with batch size of 32, learning rate of 3e-5 and linear warmup steps equal to 0.1 of the total training steps. For this quick tutorial I went for the default learning rate of the trainer class which is 5e-5, 5 epochs for training, batch size of 8 with gradient accumulation of 8 steps for an effective batch size of 64 and 200 warm up steps (roughly 10 percent of total training steps). The overall training time for this implementation was 2 hours and 54 minutes.
# define the training arguments
training_args = TrainingArguments(
output_dir = '/media/data_files/github/website_tutorials/results',
num_train_epochs = 5,
per_device_train_batch_size = 8,
gradient_accumulation_steps = 8,
per_device_eval_batch_size= 16,
evaluation_strategy = "epoch",
disable_tqdm = False,
load_best_model_at_end=True,
warmup_steps=200,
weight_decay=0.01,
logging_steps = 4,
fp16 = True,
logging_dir='/media/data_files/github/website_tutorials/logs',
dataloader_num_workers = 0,
run_name = 'longformer-classification-updated-rtx3090_paper_replication_2_warm'
)
After the training has been completed we can evaluate the performance of the model and make sure we are loading the right model.
# save the best model
trainer.save_model('/media/data_files/github/website_tutorials/results/paper_replication_lr_warmup200')
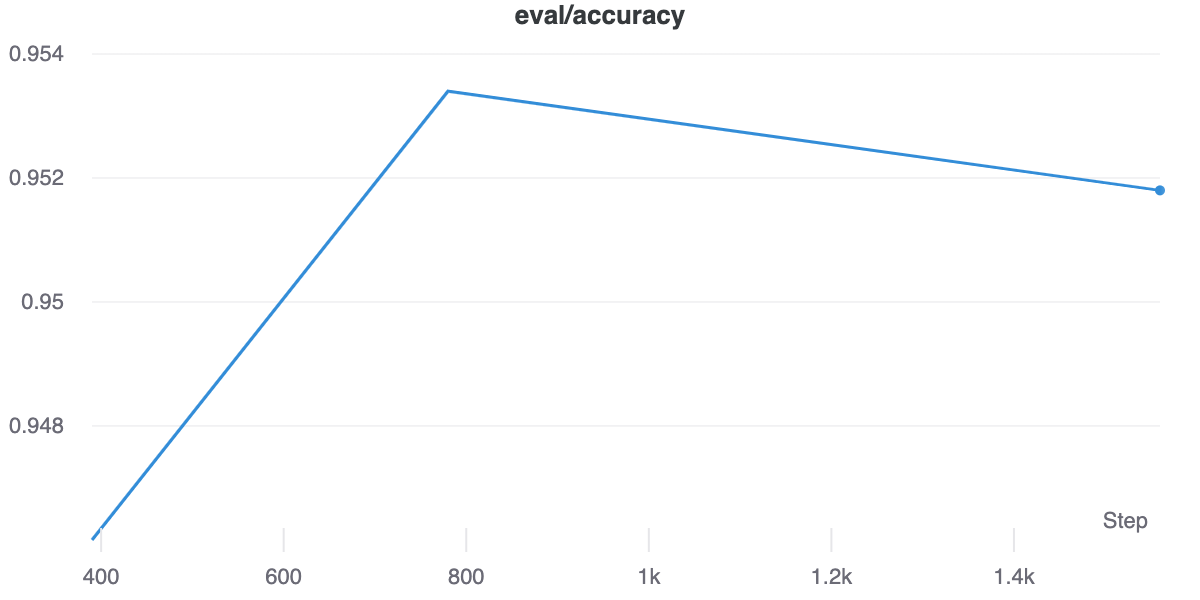
trainer.evaluate()
{'eval_loss': 0.13697753846645355,
'eval_accuracy': 0.9534,
'eval_f1': 0.9535282619968887,
'eval_precision': 0.9509109714376641,
'eval_recall': 0.95616,
'epoch': 4.9984}
The best iteration of our model achieved an accuracy 0.9534, below what the authors report (0.957). These results are probably explained by the fact that we have used several tricks to increase training speed, the use of half-precision floating-point (fp16) and the fact that we are not using their special CUDA kernel. Additionally, as the authors recognize in the paper this corpus collection is composed mostly of shorter documents thus the model does not fully utilize its capabilities to learn long sequences. Recent evaluations of the new generation of the model indicate that while longformer does not achieve the best results in any category it performs competitively across all the different tasks explored in the model evaluation, ranking second overall.
Thats it for this tutorial, hopefully you will find this helpful.
-->