Longformer Multilabel Text Classification
In this post I explore how to modify the Longformer architecture to perform multilabel classification and evaluate how much improvement does the Longformer offers in comparison with other Transformer architectures that are limited to 512 tokens like RoBERTa.
In a previous post I explored how to use the state of the art Longformer model for multiclass classification using the iris dataset of text classification; the IMDB dataset. In this post I will explore how to adapt the Longformer architecture to a multilabel setting using the Jigsaw toxicity dataset.
This data was originally published by Google as part of a Kaggle competition to identify toxic discourse in online conversations. The data contains comments from Wikipedia’s talk page edits. The competition asked participants to correctly identify if a comment belonged to one or more categories such as toxic, severe toxic, obscene, threat, insult, and identity hate. The challenge of this type of problem is that a particular document can belong to one, many or none of the categories. Research has shown that these type of problems benefit from more concise representations of the feature space; in this case the feature space can be represented by the hidden states of the token that attends to all the other tokens in a particular sequence the CLS token.
The jigsaw dataset is available on the datasets library and as of version 1.6 it can be loaded directly from the library.
from datasets import load_dataset
dataset = load_dataset("jigsaw_toxicity_pred")
I already downloaded the data so I will be importing it straight up from disk. I also modified the data loaders from the traditional pipeline of multiclass text classification and used custom data loaders. I used 90 percent of the train dataset for training and the remaining 10 percent for validation.
import torch
import pandas as pd
import numpy as np
from torch.nn import BCEWithLogitsLoss
from transformers import LongformerTokenizerFast, \
LongformerModel, LongformerConfig, Trainer, TrainingArguments, EvalPrediction, AutoTokenizer
from transformers.models.longformer.modeling_longformer import LongformerPreTrainedModel, LongformerClassificationHead
from torch.utils.data import Dataset, DataLoader
import wandb
import random
# read the dataframe
insults = pd.read_csv('../data/jigsaw/train.csv')
insults['labels'] = insults[insults.columns[2:]].values.tolist()
insults = insults[['id','comment_text', 'labels']].reset_index(drop=True)
train_size = 0.9
train_dataset=insults.sample(frac=train_size,random_state=200)
test_dataset=insults.drop(train_dataset.index).reset_index(drop=True)
train_dataset = train_dataset.reset_index(drop=True)
train_dataset
| id | comment_text | labels | |
|---|---|---|---|
| 0 | 6725d5a6391e5c77 | Goal scored for Portugal \n\nThis could be mil... | [0, 0, 0, 0, 0, 0] |
| 1 | 28ea0d2c61db3137 | My mistake someone was vandalizing the page so... | [0, 0, 0, 0, 0, 0] |
| 2 | 4de3d6b966b58ec7 | Test card F music \nCeefax music isn't the sam... | [0, 0, 0, 0, 0, 0] |
| 3 | af602c4c5f1b09bc | ":Meh, I guess I can live with either outcome,... | [0, 0, 0, 0, 0, 0] |
| 4 | 9e412a7965873237 | UV is my error, above. I'm told by Kimberly Ja... | [0, 0, 0, 0, 0, 0] |
| ... | ... | ... | ... |
143614 rows × 3 columns
The traditional LongformerForSequenceClassification instance on the HuggingFace Transformers library handles multiclass classification by default, so we need to modify it for our multilabel use case. Fortunately all of the different components are available on the Transformers library. For this we use a raw LongformerPreTrainedModel class and add a classifier head on top that will take the pooled output of the LongFormer model. This pooled output consists of the last hidden-state of the first token of the sequence, the CLS classification token, processed by a linear layer and a tanh activation function and passes it through the classification head (for more details you can see the original documentation of the Longformer model). We also replace the Cross Entropy loss with a Binary Cross-Entropy Loss. This post by Daniel Godoy does a pretty good job at explaining this loss function and includes nice visualizations.
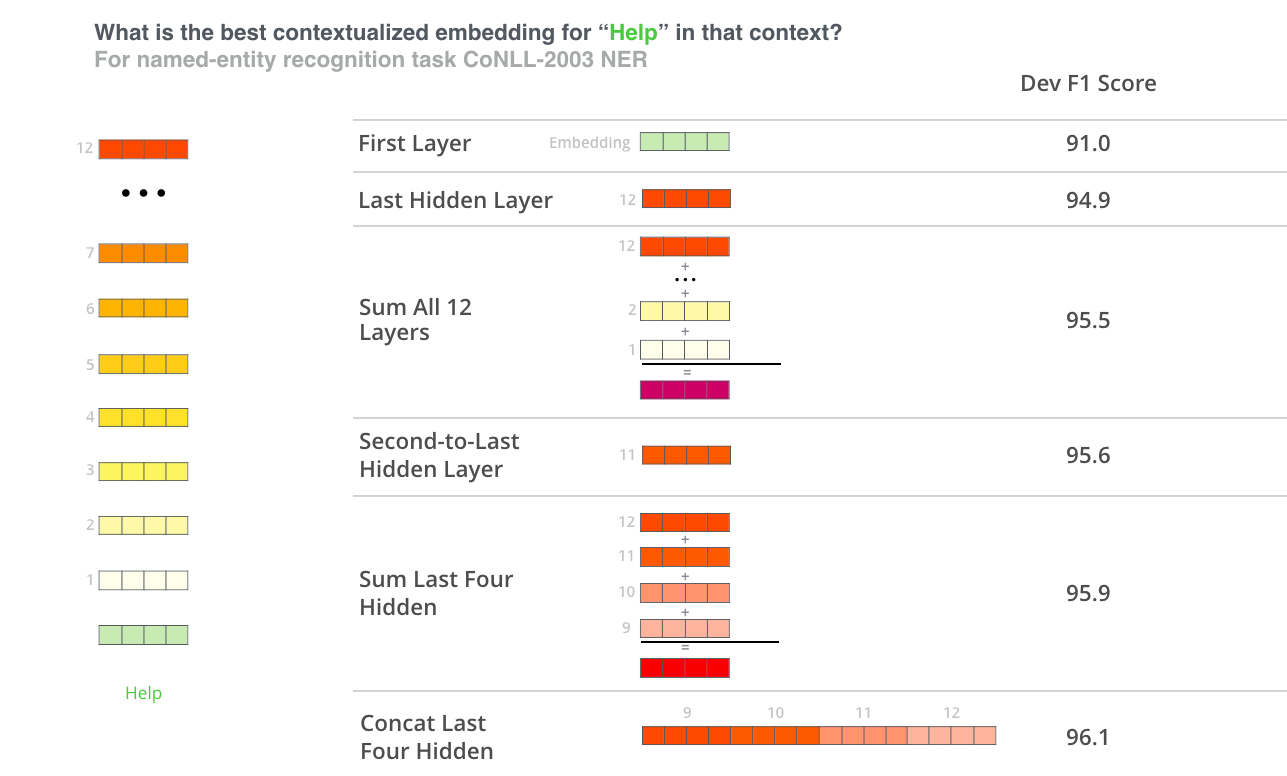
Using the last hidden layer of the CLS token is the default method of pooling for the Transformers library. However the authors of the BERT paper suggest that a concatenation of the last 4 hidden layers shows the greatest performance in downstream tasks. You can see the different choices of hidden states configurations in the illustration below, taken from Jay Alammar’s blog. I will explore a version of this classification using pooled outputs in a future post.
Below you will find the final class that holds the full model:
# instantiate a Longformer for multilabel classification class
class LongformerForMultiLabelSequenceClassification(LongformerPreTrainedModel):
"""
We instantiate a class of LongFormer adapted for a multilabel classification task.
This instance takes the pooled output of the LongFormer based model and passes it through a classification head. We replace the traditional Cross Entropy loss with a BCE loss that generate probabilities for all the labels that we feed into the model.
"""
def __init__(self, config):
super(LongformerForMultiLabelSequenceClassification, self).__init__(config)
self.num_labels = config.num_labels
self.longformer = LongformerModel(config)
self.classifier = LongformerClassificationHead(config)
self.init_weights()
def forward(self, input_ids=None, attention_mask=None, global_attention_mask=None,
token_type_ids=None, position_ids=None, inputs_embeds=None,
labels=None):
# create global attention on sequence, and a global attention token on the `s` token
# the equivalent of the CLS token on BERT models. This is taken care of by HuggingFace
# on the LongformerForSequenceClassification class
if global_attention_mask is None:
global_attention_mask = torch.zeros_like(input_ids)
global_attention_mask[:, 0] = 1
# pass arguments to longformer model
outputs = self.longformer(
input_ids = input_ids,
attention_mask = attention_mask,
global_attention_mask = global_attention_mask,
token_type_ids = token_type_ids,
position_ids = position_ids)
# if specified the model can return a dict where each key corresponds to the output of a
# LongformerPooler output class. In this case we take the last hidden state of the sequence
# which will have the shape (batch_size, sequence_length, hidden_size).
sequence_output = outputs['last_hidden_state']
# pass the hidden states through the classifier to obtain thee logits
logits = self.classifier(sequence_output)
outputs = (logits,) + outputs[2:]
if labels is not None:
loss_fct = BCEWithLogitsLoss()
labels = labels.float()
loss = loss_fct(logits.view(-1, self.num_labels),
labels.view(-1, self.num_labels))
#outputs = (loss,) + outputs
outputs = (loss,) + outputs
return outputs
The new class returns the loss and the outputs that we will use to evaluate the performance of the model. Just as with BERT based models we specify the sequence length and a auxiliary class to handle the data preparation and ingestion into the model. I experimented with different sequence length configurations and decided to go with 3048 tokens.
# instantiate a class that will handle the data
class Data_Processing(object):
def __init__(self, tokenizer, id_column, text_column, label_column):
# define the text column from the dataframe
self.text_column = text_column.tolist()
# define the label column and transform it to list
self.label_column = label_column
# define the id column and transform it to list
self.id_column = id_column.tolist()
# iter method to get each element at the time and tokenize it using bert
def __getitem__(self, index):
comment_text = str(self.text_column[index])
comment_text = " ".join(comment_text.split())
# encode the sequence and add padding
inputs = tokenizer.encode_plus(comment_text,
add_special_tokens = True,
max_length= 3048,
padding = 'max_length',
return_attention_mask = True,
truncation = True,
return_tensors='pt')
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
labels_ = torch.tensor(self.label_column[index], dtype=torch.float)
id_ = self.id_column[index]
return {'input_ids':input_ids[0], 'attention_mask':attention_mask[0],
'labels':labels_, 'id_':id_}
def __len__(self):
return len(self.text_column)
batch_size = 2
# create a class to process the training and test data
tokenizer = AutoTokenizer.from_pretrained('allenai/longformer-base-4096',
padding = 'max_length',
truncation=True,
max_length = 3048)
training_data = Data_Processing(tokenizer,
train_dataset['id'],
train_dataset['comment_text'],
train_dataset['labels'])
test_data = Data_Processing(tokenizer,
test_dataset['id'],
test_dataset['comment_text'],
test_dataset['labels'])
# use the dataloaders class to load the data
dataloaders_dict = {'train': DataLoader(training_data, batch_size=batch_size, shuffle=True, num_workers=4),
'val': DataLoader(test_data, batch_size=batch_size, shuffle=True, num_workers=4)
}
dataset_sizes = {'train':len(training_data),
'val':len(test_data)
}
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
When the model is instantiated you will see a warning indicating that the model needs to be pretrained in a downstream task. This is normal since the model was pretrained for language modelling and the weights for the classification task need to be finetuned.
model = LongformerForMultiLabelSequenceClassification.from_pretrained('allenai/longformer-base-4096',
gradient_checkpointing=False,
attention_window = 512,
num_labels = 6,
cache_dir='/media/data_files/github/website_tutorials/data',
return_dict=True)
I also decided to add additional metrics to evaluate the performance of the model such as F1 Score, Accuracy and Area Under the Receiver Operating Characteristic Curve Score roc_auc_score. The trainer class from Transformers allows us to easily feed specific metrics in the evaluation by feeding a function that takes the predictions and labels and returns the metrics as a dictionary to the compute metrics argument; in this case I followed the HuggingFace documentation and created another compute metrics function and feed the EvalPrediction class.
from sklearn.metrics import f1_score, roc_auc_score, accuracy_score
def multi_label_metrics(
predictions,
labels,
):
sigmoid = torch.nn.Sigmoid()
probs = sigmoid(torch.Tensor(predictions))
y_pred = np.zeros(probs.shape)
y_true = labels
y_pred[np.where(probs >= 0.5)] = 1
f1_micro_average = f1_score(y_true=y_true, y_pred=y_pred, average='micro')
roc_auc = roc_auc_score(y_true, y_pred, average = 'micro')
accuracy = accuracy_score(y_true, y_pred)
# define dictionary of metrics to return
metrics = {'f1': f1_micro_average,
'roc_auc': roc_auc,
'accuracy': accuracy}
return metrics
# Use the aux EvalPrediction class to obtain prediction labels
def compute_metrics(p: EvalPrediction):
preds = p.predictions[0] if isinstance(p.predictions,
tuple) else p.predictions
result = multi_label_metrics(
predictions=preds,
references=p.label_ids)
return result
# define the training arguments
training_args = TrainingArguments(
output_dir = '/media/data_files/github/website_tutorials/results',
num_train_epochs = 4,
per_device_train_batch_size = 2,
gradient_accumulation_steps = 64,
per_device_eval_batch_size= 16,
evaluation_strategy = "epoch",
disable_tqdm = False,
load_best_model_at_end=True,
warmup_steps = 1500,
learning_rate = 2e-5,
weight_decay=0.01,
logging_steps = 8,
fp16 = False,
logging_dir='/media/data_files/github/website_tutorials/logs',
dataloader_num_workers = 0,
run_name = 'longformer_multilabel_paper_trainer_3048_2e5'
)
# instantiate the trainer class and check for available devices
trainer = Trainer(
model=model,
args=training_args,
train_dataset=training_data,
eval_dataset=test_data,
compute_metrics = compute_metrics,
#data_collator = Data_Processing(),
)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
trainer.train()
For the training procedure I fine tuned the classifier for 4 epochs, with a batch size of 2 and 64 accumulation steps for an effective batch size of 128. I also use a linear schedule with warmup (similar to the BERT paper) for 1500 steps. In the original paper the authors trained for 15 epochs on the IMDB data but while the training loss continued to decrease the evaluation loss started to go up after the third epoch.

Using a sequence length of 3,048 tokens results in a private leaderboard score of the Kaggle competition of 0.98587, which would have put the model around the top 25 percent of submissions, not impressive but also not terrible considering the winning submission won thanks to a combination of data augmentation, ensemble of embeddings, and Rough-bore pseudo-labelling strategies.
trainer.model.save_pretrained('/media/data_files/github/website_tutorials/results/longformer_base_multilabel_3048_2e5')
tokenizer.save_pretrained('/media/data_files/github/website_tutorials/results/longformer_base_multilabel_3048_2e5')
The training time for the Longformer is substantially higher than it takes for other Transformer architectures. Training for 4 epochs on a RTX 3090 took 2 days and almost 7 hours!. For comparison a RoBERTa model on the same data with sequence length of 512 tokens takes 2h 24m 54s and delivers a score on the Kaggle leaderboard of 0.98503, enough to land on the top 31 percentile. So depending on the application it may not be feasible or desirable to use this model.
Conclusion
In this tutorial I showed how to use the Longformer architecture in a multilabel setting. The performance of the model is superior to what you can obtain out of the box with a RoBERTa model. However training time of the model is substantially higher than for a first generation Transformer. This issue has been documented before (see here and here) and may be related to the fact that in the original paper the authors implemented their own custom CUDA kernel. This model will also yield higher performance with further pre-processing of the input data (e.g. cleaning the vocabulary) and using backtranslation to increase the size of the pretraining dataset. Finetuning the language model is another possibility to increase the performance of the model, however given the constraints of size and speed that may be a burdensome process for the average deep learning practitioner.
You can find the full code of this tutorial here.