Big Bird Text Classification Tutorial
In this post I explore one of the most innovative models that are part of the long range Transformers; Big Bird by researchers at Google. This post provides a quick description of what the main innovations of the model are and gives a tutorial on how to apply it to a text classification problem.
Big Bird is part of a new generation of Transformer based architectures (see Longformer, Linformer, Performer) that try to solve the main limitation of attention mechanisms; the quadratic nature of attention. The Big Bird architecture, just as the Longformer that I explored in a previous post , expands the number of tokens that the model can process from 512 to 4,096 thanks to a new attention mechanism known as Block Sparse Attention. This flavor of attention uses a combination of global attention (on selected tokens), window attention (just like Longformer) and random attention. See the illustration of the original paper below.
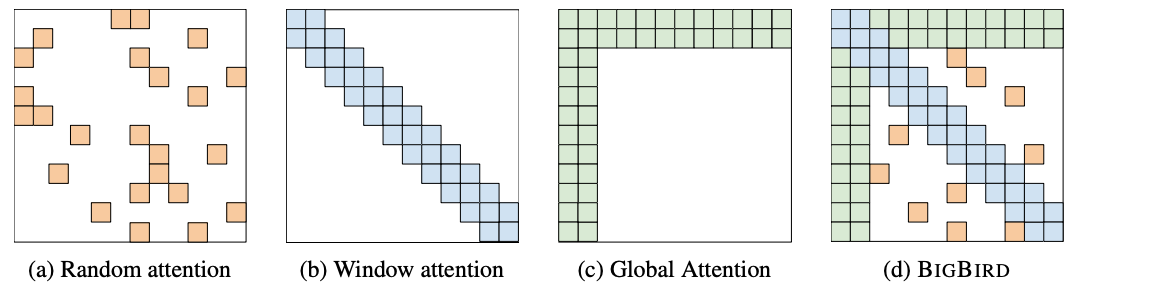
The authors use random attention in addition to window attention and selected global attention to retain as much information as possible from the original full attention without incurring in the memory costs. In regular full attention all tokens attend to each other thus resulting in nxn memory complexity. This in turn means that if the model wants to query information from one token to another the shortest path (as understood in network science) between tokens would be 1 since this is a fully connected graph (all nodes are connected to each other and are one degree separated). By using a combination of global attention on selected tokens like CLS, window attention (like Longformer) and random attention, the model can effectively reach a performance that is very close to full attention without incurring in the full cost of every token attending to each other.
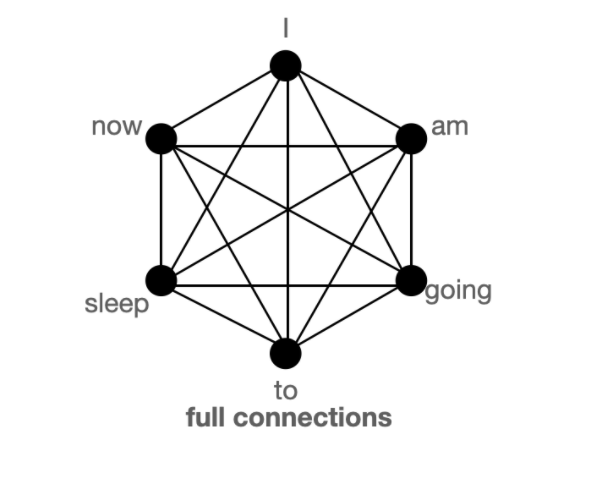
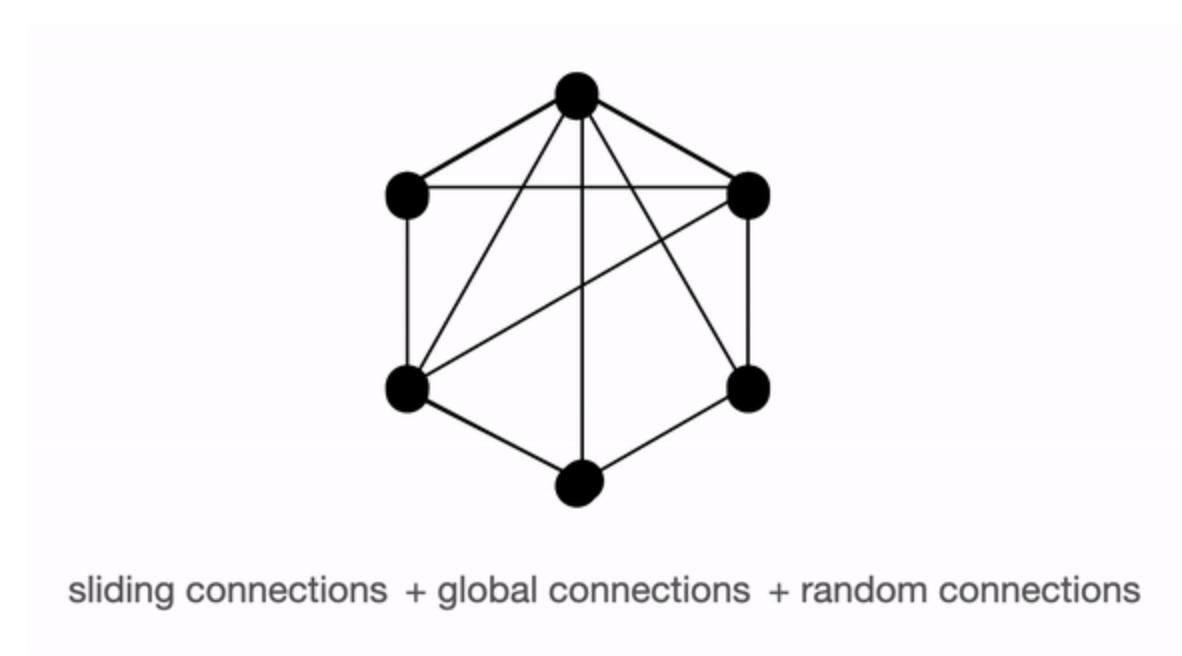
More specifically Big Bird utilizes the properties of information diffusion in the context of a directed network with properties similar to small world networks, where nodes are highly clustered and have efficient information transfer. The authors provide demonstration in their paper and show that this type of attention approximates full attention. This post by Vasudev Gupta shows how a combination of these three types of attention is very similar to full attention and presents a really nice graphical depiction (see below) of their theory. The video by Yannic Kilcher explaining the model also does a fantastic job at illustrating this concept.
Full attention where each token connects to each other
Block sparse attention approaching similar performance to full attention
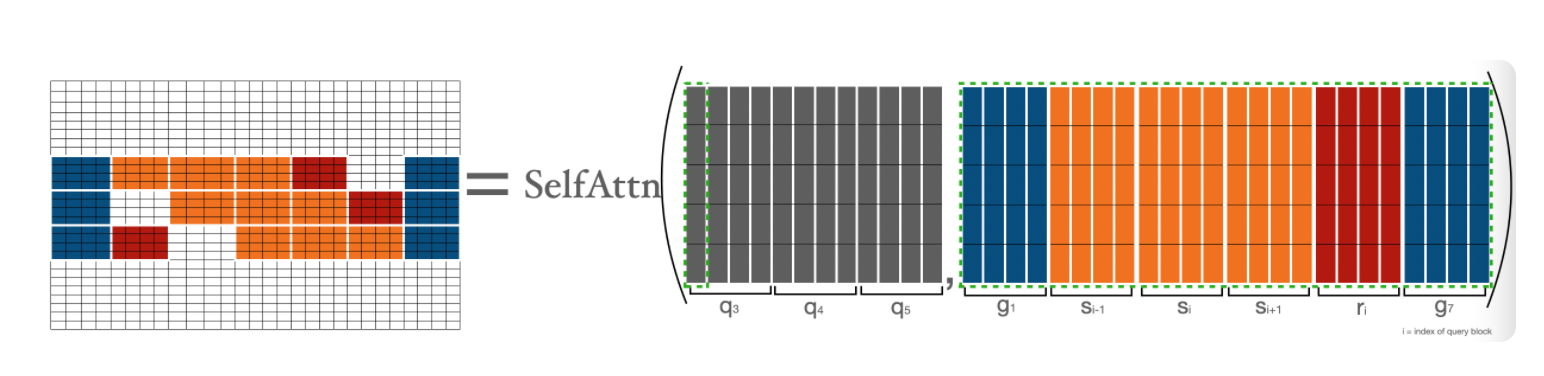
The usage of this ‘irregular’ attention pattern does pose some additional challenges for GPU computing as it would result in sparse matrix multiplication. To address this the authors pass the different attentions as blocks so that the matrix multiplication is done efficiently. Vasudep Gupta also does a great job at describing the steps for this process, and the image below taken from his post shows how different color coded types of attention are packed together in a block so that the GPU can process the necessary dot products of queries and vectors.
All these engineering tricks result in less computational complexity which is good in certain tasks as they approach the performance of full attention and as a result they achieve SOTA in summarization and QA. The model was trained on the Books, CC-News, Stories, and Wikipedia datasets using the sentencepiece vocabulary of RoBERTa. They also warm started from RoBERTa’s checkpoint, which accelerated the training of the model.
It is also worth nothing that some of these results were achieved using a slightly modified architecture known as ETC (the architecture with random attention is known as ITC), which contains more global tokens and does not use random tokens. The current implementation on Hugging Face only supports the ITC version of the model. The authors recognize that on other tasks such as document classification the performance may be marginally better. This will become apparent once we train a model and evaluate the trade off of improvement in performance vs complexity/time to fine tune the model.
Now lets see how the model performs on the IMDB dataset. For this exercise I use the bare minimum number of tokens recommended (1,024) to implement random attention rather than the full sequence as the training is really slow. Also it is important to know that the sequence length needs to be divisible by block size.
We load the necessary libraries.
import torch
import datasets
import transformers
import pandas as pd
import numpy as np
from transformers import BigBirdTokenizer, \
BigBirdForSequenceClassification, Trainer, TrainingArguments,EvalPrediction, AutoTokenizer
from torch.utils.data import Dataset, DataLoader
import wandb
import random
We can also use the datasets library to use the IMDB dataset.
train_data, test_data = datasets.load_dataset('imdb', split =['train', 'test'],
cache_dir='/media/data_files/github/website_tutorials/data')
When we load the model for sequence classification the model will let us know that some of the weights are unused and that we need to train further if we wish to use it in downstream tasks.
# load model and tokenizer and define length of the text sequence
model = BigBirdForSequenceClassification.from_pretrained('google/bigbird-roberta-base',
gradient_checkpointing=False,
num_labels = 2,
cache_dir='/media/data_files/github/website_tutorials/data',
return_dict=True)
Some weights of the model checkpoint at google/bigbird-roberta-base were not used when initializing BigBirdForSequenceClassification: ['cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.decoder.weight', 'cls.predictions.decoder.bias', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias']
- This IS expected if you are initializing BigBirdForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BigBirdForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BigBirdForSequenceClassification were not initialized from the model checkpoint at google/bigbird-roberta-base and are newly initialized: ['classifier.dense.weight', 'classifier.dense.bias', 'classifier.out_proj.weight', 'classifier.out_proj.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
tokenizer = AutoTokenizer.from_pretrained('google/bigbird-roberta-base',
max_length = 1024,
cache_dir='/media/data_files/github/website_tutorials/data',)
# define a function that will tokenize the model, and will return the relevant inputs for the model
def tokenization(batched_text):
return tokenizer(batched_text['text'], padding = 'max_length', truncation=True, max_length = 1024)
train_data = train_data.map(tokenization, batched = True, batch_size = len(train_data))
test_data = test_data.map(tokenization, batched = True, batch_size = len(test_data))
# define accuracy metrics
from sklearn.metrics import precision_recall_fscore_support, accuracy_score
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='binary')
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}
The authors in the paper used a batch size of 64 for text classification tasks, a learning rate of 1e-5 with a warmup schedule for the first 10 percent of steps and trained for 40 epochs!. However the training speed of the model is quite slow so training for 40 epochs on a single GPU (even on the mighty 3090) is not a realistic scenario; the researchers trained their model on a cluster of 16 TPU’s-v3.
# define the training arguments
training_args = TrainingArguments(
output_dir = '/media/data_files/github/website_tutorials/results',
num_train_epochs = 4,
per_device_train_batch_size = 2,
gradient_accumulation_steps = 32,
per_device_eval_batch_size= 16,
evaluation_strategy = "epoch",
disable_tqdm = False,
load_best_model_at_end=True,
warmup_steps=160,
weight_decay=0.01,
logging_steps = 4,
learning_rate = 1e-5,
fp16 = True,
logging_dir='/media/data_files/github/website_tutorials/logs',
dataloader_num_workers = 0,
run_name = 'bigbird_classification_1e5'
)
# instantiate the trainer class and check for available devices
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_data,
eval_dataset=test_data
)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
device
# train the model
trainer.train()
Training on the IMDB model for 4 epochs takes 5h 53m 30s vs the 2h 9m 8s for RoBERTa and the 2h 54m 55s of Longformer with the same sequence length. And while the model achieves an impressive 95.73 accuracy score; a more realistic score would probably hoover around 95.50 given variation on the training process. The relative improvement over RoBERTA of 0.20 points in accuracy at the cost of twice the training time when compared to Longformer and 3 times when compared to RoBERTa should give you pause when considering using this model in production.
Accuracy of Big Bird across 4 epochs

Conclusion
Big Bird is one of the most innovative long range transformer architectures that try to solve the problem of quadratic memory. While the authors are able to increase the sequence size, the training of the model becomes more burdensome given all the different parameters that need to be optimized and the transformations required. A marginal improvement over a model that is 3 times faster (RoBERTa) may not make this model feasible in prodution environments, specially with limited resources.
That is it for this tutorial hopefully you find this helpful. The full version of the notebook is here.